How to create complex GPTs with API actions and a Node.js backend

Introduction
There are 4 types of GPTs you can create:
- Basic GPT. It takes user input, processes it according to the instructions and returns the output. It may browse the internet, and use code interpreter, and Dalle to execute python functions and produce images.
- GPT with knowledge. Same as basic GPT, but it also references additional knowledge that you attach to it. It can be useful if you have a specific domain knowledge that is either secret, or unlikely to have been included into the LLMs training data due to its specificity or novelty.
- GPT with actions (API). These GPTs can interact with the APIs using actions. Actions are HTTP methods described in the OpenAPI (formerly Swagger) schema. These GPTs only work with APIs which authentication method is compatible with OpenAi. For example: they can call Google Calendar API because Google Oauth is compatible with OpenAi. But they can’t call Figma directly because the latter expects data in a different format from what OpenAi sends. Therefore, to make a Figma GPT you need to write an adapter (a middleware function on your backend) that would manipulate the requests sent by OpenAi. Which brings us to the next type of GPT.
- GPT with actions and backend. This is the most complex type of GPTs that calls the APIs on your backend. It involves building a backend in the form of a server or serverless functions, and call the 3rd party APIs within them. You then make your GPT call your backend instead of calling the 3rd party APIs directly. This way you can intercept data in between your GPT and 3rd party APIs, process, sanitize, save it, or perform other operations based on your use case. This is useful when a 3rd party service that you need to integrate with has Oauth 2.0. PCKE authentication, which is not supported by OpenAi (at the time of writing). In such cases you have to implement the authorization and token exchange functions on your backend that would modify the structure of the requests coming from the OpenAi to satisfy the 3rd party server’s expectations, as well as the responses returned by the 3rd party server to satisfy the OpenAi GPT’s settings (if they don’t already). More on this later. Another use case for this type of GPTs is when you want to process the data coming from the GPT or the response coming from the 3rd party api, before sending it back to the GPT. For example, if your GPT works with user preferences, you might want to save them into a database to reference them later for making responses more personalized. Or it might be that the 3rd party api returns too much data, most of which you don’t need, leading to the ResponseTooLarge error. In these cases, you have to step in between your GPT and the 3rd party api and clean the response from the unnecessary information.
The number of use cases for GPTs with backend is huge. That’s why it appears to be the future of the GPT building.
Takeaways:
- Basic GPTs can browse internet, execute complex calculations with python code, create images, and process user instructions with inbuilt LLM knowledge.
- GPT with knowledge is a basic GPT with custom files attached to it.
- GPT with actions is when you add the ability to call an API (someone’s server) to a basic GPT.
- GPT with actions and backend is when you build an infrastructure (backend) and connect your GPT to it as the user acquisition point. The know how is stored largely on the backend, not GPT.
Building a GPT with a backend
Let’s look at how to create a GPT with actions and backend in detail. This will cover everything that is also applicable to the simpler types of GPTs.
The paradigm
When GPTs just rolled out it appeared that they are capable of doing any task, since they are backed by the GPT4 model. However, in practice it turned out that custom GPTs are very limited (far more limited than the GPT4 API). Obviously, this is not official information, and it kind of doesn’t make sense because custom GPTs are supposed to be using the GPT4 API under the hood, but the difference in performance is evident for everyone who spent some time working with GPT4 API before custom GPTs have been rolled out.
And this makes sense, because while GPT4 API is paid, custom GPTs are free, and it’s expected that OpenAi would want to limit their resources for obvious reasons.
With this in mind the paradigm of building GPTs with a backend should be: to see the GPT as the user acquisition and data formatting gate only – not the engine for calculations. The role of the GPT is to understand the user’s request, format it accordingly, and send the data to the api that does the heavy lifting.
If you build your GPT with this paradigm, the instructions will be shorter, and your GPT will give more consistent replies. But at the same time the GPT will be more expensive to run, because you'll have to do the heavy lifting on the backend, which costs money. Everything has a downside.
The principles
In building GPTs there are 4 principles that greatly influence the outcomes.
How you write the instructions
Brevity and meaning. Similar to human conversations — the fewer meaningless words you say — the better is the outcome. But unlike humans who often have to say meaningless words for the sake of politeness, ChatGPT is not expecting that, which gives you more room to perfect your expressions.
That’s why, when you’re writing instructions avoid using meaningless words. This will make your instructions shorter helping the bot comprehend them better.
This is because it appears like the GPT is skipping words when your prompt gets longer. As if it’s randomly choosing some maximum number of sentences that fit its memory. And because this problem appears only with long instructions, it’s safe to assume that brevity increases the stability of results.
With this in mind, here are a few examples of how you can modify your vocabulary for brevity:
- Could you please do → do.
- I would like you to do → do.
- Feel free to → you can.
- Your main task is to provide → you provide.
- This approach allows you to handle → this way you can.
- Use your browsing tool to find → browse to find.
As a general rule, you can always make your initial prompt 25% smaller, and if you do it correctly, it will increase the likelihood of the bot following your instructions.
Tip: After shortening a sentence ask yourself if it has the same meaning? If yes — keep the short version.
Modularity of meaning. This is about structuring your instructions such that parts related to the same actions are grouped together. This is especially important for longer instructions with many different actions.
Here is the pattern I found to be working best in a 720 words long prompt:
- If the user asks for … do this: 1) tell that … 2) call the getTestAction to ... 3) …
- If the user shares … do this: 1) tell that … 2) use the saveTestAction to ... 3) …
- If the user asks about … do this: 1) tell that … 2) if you don't know the … 3 …
The hypothesis here is that GPT ignores the instructions if the initial condition is false which leaves it more resources for better following the truthy conditions.
Yelling. I am a little worried that some day ChatGPT may remind me of each time I yelled at it in my instructions, but I still do it because it improves results. Writing the most important aspects of your instructions in uppercase increases their likelihood of being comprehended in every invocation. Here is how I typically do it:
Follow these steps strictly step-by-step:
- …
- …
- …
This instruction is useful only for steps that must be taken all the time. Obviously, you should remove optional steps from the numbered list.
Another use case:
This helps ensure that the bot includes the required param while calling an action.
Key point duplication. Saying twice helps people comprehend better. Likewise, saying twice helps robots comprehend better. However, it only works if you’re saying twice 1 or 2 instructions. The hypothesis is again — that the bot skips lines (or sentences) in large prompts, and so by including multiple copies of a critical sentence you increase its likelihood of execution. Obviously, this won’t work if you duplicate all of the sentences.
Giving examples. If you need your bot to output structured data in a consistent format, giving examples is a must. Otherwise, each new response will often have something different.
Here is an example of giving an example:
How you write the OpenApi manifest
I assume that you know what OpenApi manifest is. If not, you should get familiar with it if you are into building GPTs.
Add only the necessary data points. When writing an OpenApi manifest it’s crucial to include only the information your GPT will need. The excess datapoints create additional text that you GPT will have to understand, and therefore it can negatively influence the comprehension of the instructions. This is because ultimately both the instructions and the manifest are combined into a single string that is fed into the model. And the shorter this final string is the higher is the likelihood of every detail to be comprehended by the robot. That’s why just like you need to keep your instructions clean and to the point, you should also keep the OpenApi manifest clean and to the point.
Add descriptive descriptions. Almost every datapoint in the manifest can have descriptions. These used to be important for humans, now they are important for the robots. When your GPT receives the input from the user, or a response from the API, it uses the descriptions from your manifest to understand how to interpret it best. That’s why when you add a short and descriptive description to each data point you increase the likelihood that your GPT is going to call a correct action, or interpret the results correctly. Examples:
How you return the data from the backend
Filter the response. GPTs have a limit of data they can ingest. If the response from an api exceeds this limit the GPT throws a ResponseTooLarge error. To resolve this problem you need to filter the irrelevant data from the response. Usually by including certain parameters such as ‘limit’, ‘filter’ or ‘select’ to the request. But if the API you’re calling doesn’t give you the ability to filter the response the only way to make it work is to carry the API execution to your backend where you can filter the response using JavaScript or python.
In the node.js environment you typically create an express server and host it in the cloud, such as AWS EC2 or Digital Ocean Droplets. In your server you write a function for calling the 3 party’s API and expose it’s endpoint. Then you add this endpoint to the OpenApi manifest of your GPT. Your GPT calls your function and your function calls the 3 party API, and then filters the response, and ultimately sends the filtered response back to the GPT. Not only this solves the ResponseTooLarge error, but it also improves the performance of the GPT, because of less irrelevant data.
Note: You don’t have to set up a server to call 3 party APIs from your backend. You can also do it via serverless functions such as the AWS Lambda, DO Serverless Functions, or alike. Same idea — slightly different implementation.
Now, let’s create a GPT with a backend
The authentication:
When creating a GPT with a backend you have to secure your API somehow, to prevent others from accessing your API outside of your GPT. This is important because when GPT calls an action it will show your server’s url. And even though it won’t show the exact endpoint, diligent people will spend time trying all possible variations until they find an existing one. And when they find it it’s important that it’s secured so that they can’t get anything out of it.
The security options include:
- Basic authorization – issuing a login and password for the GPT.
- Issuing an API key for the GPT.
- Issuing a JWT token for each user (setting up a custom authorization server).
- Implementing a 3 party OAuth2 (Sign in with Google, Sign in with Facebook, etc…).
In this guide we'll be using the OAuth method as it's the most widely used authentication method.
I typically start with the hardest parts first, so let’s set up the backend, then create the openapi manifest, and lastly add the instructions to the GPT.
For this tutorial I’ll be using AWS lambda as a backend.
Since this GPT is going to have a google Oauth2 authentication, I have to create 2 more endpoints — one for authorization (for receiving the authorization code), and one for the authentication (for exchanging the authorization code for the access_token) in addition to my data api endpoints.
So head over to your aws account, and then type Lambda in the search bar. When on Lambda dashboard page, click ‘Create function’.
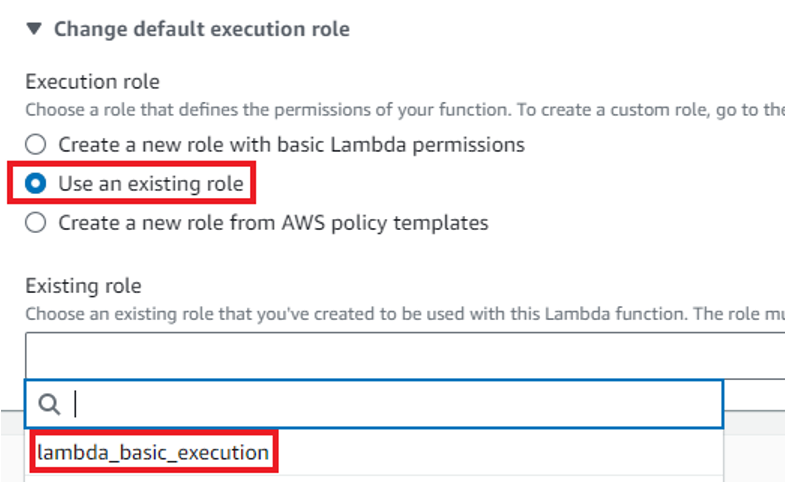
If you are the owner of the account you will not need to change the default execution role. I’m using a service account with limited permissions, therefore I have to do it. I select “Use existing role” and then from the dropdown I select a role available for me. After that click “Advanced settings” and check the “Enable function URL”, and then set the Auth type to “NONE”.
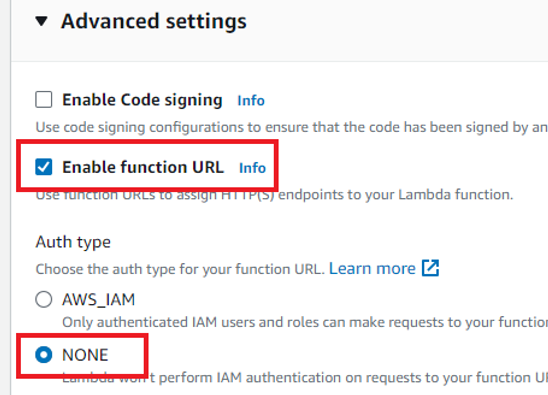
This is to make your function callable outside of your AWS account.
Click “Create function” in the bottom right corner. This will create your function and give you a template code to start with. It looks like this:
The entry point to your function is the Function URL on the right:
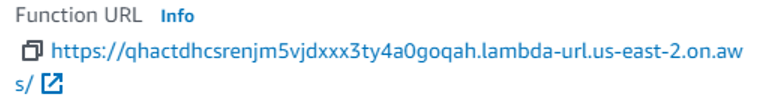
If you click it, you should see the “Hello from Lambda” text in your browser.
We will need to swap the content of this function, and for that we head to the documentation of the OAUTH provider that we're going to implement. In this example we implement Google Oauth because it has the widest user base.
After you read the documentation you should come to the realization that to implement Google OAuth you need 3 pieces of information:
- Google Client ID
- Google Client Secret
- Redirect URL
The redirect URL will be you GPT’s callback url, and the other two parameters you will get after you create a google app.
To create a Google app head over to the Google Console at Dashoard. After you land on that page, you’ll be prompted to create a project, please do it. After you’ve created a project navigate back to Dashoard. Then in the left hand side menu click the “OAuth consent screen” option.
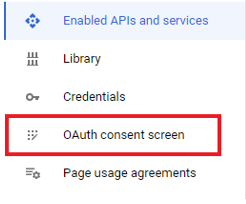
Select your user type as “External” if you app is going to be public.
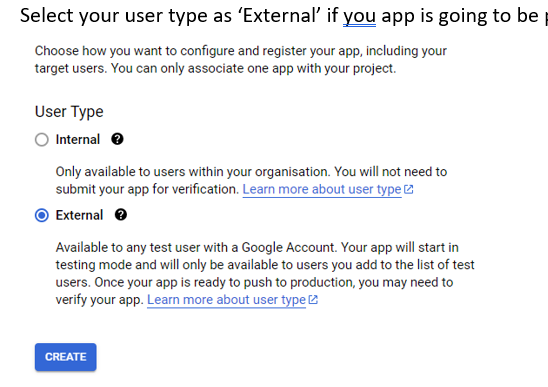
Then fill in the information about your app. This info will be what the users see when the grant their consent for authorizing your app.
Next you can upload a logo if you want. But I don't recommend it because if you do it your app will require verification that may take 4 weeks. If you don’t upload the logo your app might not need verification.
In the App domain section enter the “chat.openai.com” because your app is hosted there and the privacy policy and terms of service URLs should be of the Openai as well.
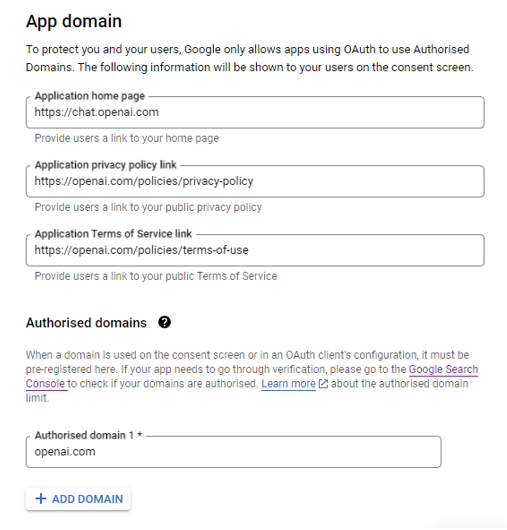
Click “Update” and then “Save and continue”. Here you should add the email of a test user. This person will be able to use your app in the test mode.
Click “Save” and then “Back to dashboard”. Your consent screen is now ready and you can click “Publish app” to save yourself from the hassle of doing this later on.
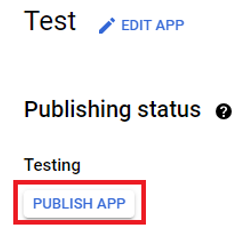
After you publish your app everybody will be able to use it.
Now, it’s time to create the credentials — the Google Client ID, and Google Secret ID, that we will need for the OAuth. For that click the “Credentials” option in the left hand menu.
Then at the top click “Create credentials” and select “OAuth Client ID” from the options.
On the newly opened screen select the Application type as “Web application”, give it an arbitrary name, e.g. “Web” and in the Authorized JavaScript origins add https://chat.openai.com.
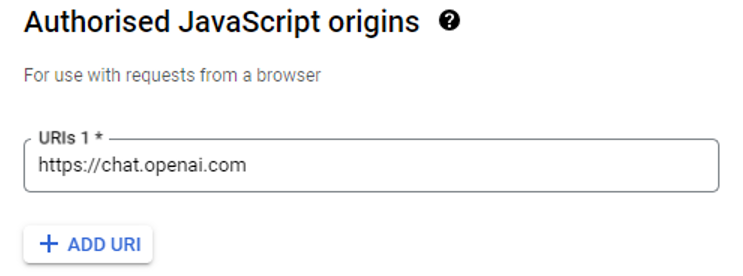
Then in the Authorized redirect URIs add the same https://chat.openai.com again. We’ll have to change it later after our GPT is ready, but for now you can set this value to https://chat.openai.com.
Click “Create”.
You will be shown your client ID and Client secret. Copy them into a text document, or download as JSON. Now we have everything to setup the OAuth flow on our backend. Let’s head back to Lambda. This is the placeholder code we have in our lambda function.
Let’s copy it to our code editor, because we’ll need to install some modules, which is not possible inside Lambda’s native editor. So create a folder on your desktop, called googleAuthorization, and then create a file in it called index.js. Then enter this folder in the vscode or a similar editor. Then run this command in your terminal
Now we need to extract the OAuth2 method from the google object. It allows us to create a client object using our Google Application ID, Google Application Secret, and Redirect URI.
Now, let’s create the client.
You are free to use env variables for storing your secrets as this is a good practice, but I skip them here and instead paste the strings directly for the sake of simplicity.
After you’ve created the client, go ahead and construct the loginLink using the generateAuthUrl method from the client you've just created.
If you’re using some other backend, like express.js you’ll extract the state like this
By this point your code should look like so:
In the above code we’ve created the loginLink, now we need to tell the GPT to redirect the user to it.
For that we need to modify the response and add a location header with the loginLink value that we’ve generated, like this:
We also set the statusCode to 302 to notify the GPT that it must redirect the user.
The final code looks like this:
The first stage of the flow is completed. This function will redirect the user to the consent screen we created earlier in Google Console.
Now we need to pack it in a zip file to upload to Lambda. This is because it contains node_modules that also have to be uploaded, because Lambda doesn't download the modules itself.
So go to your desktop and enter your googleAuthorization folder.
Select all files and create a zip file from them.
Then go to your lambda function, make sure you are in the “Code” tab and click “Upload from” button on the right.
and then select the ‘.zip’ format to upload your zip file. This is it for the first — authorization function.
Unlike the first function that receives a GET request, this function will receive the code in a POST request (because this is how the GPT sends these requests). Therefore the ‘code’ parameter has to be extracted from the body of the request.
But here is a caveat. When GPT sends the payload it encodes it in base64. Therefore, you have to convert the base64 string into normal string, and then parse it into an object.
Here is a function that does just that. Obviously created by ChatGPT.
If you also want to extract the email of the user to save it to your database you can do it like this.
So far your code should look like this:
With this in mind the final code would be:
I'm familiar with mongodb, so in this example we're using mongodb. First, head over to mongodb and create an account if you don't have one already. Select the free plan.

While creating the deployment you'll be prompted to create a user and a password for the user.
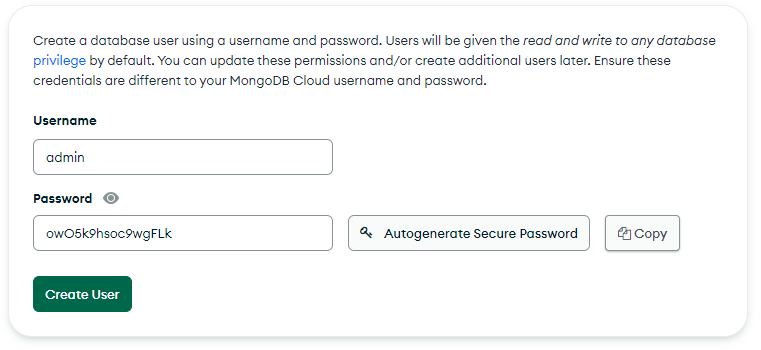
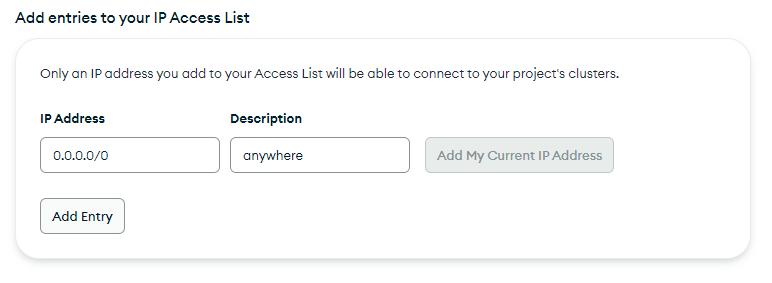
Call the user “admin” and generate a secure password for it. Then copy this info somewhere as we will use it to connect to the database. Also, while creating the deployment add the 0.0.0.0/0 ip address in the allow list, to allow connection from anywhere. You can also research the ip address of your exact lambda function and add it instead, which will be a better approach, but I don't know how to do it and so we're doing it this way.
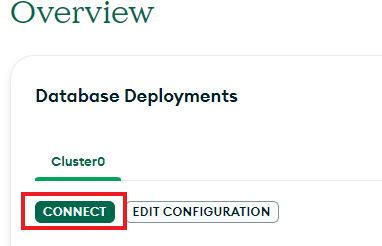
After creating the deployment, click “Connect”
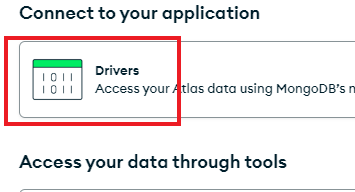
and then select “Drivers”.
Then copy the connection string template.
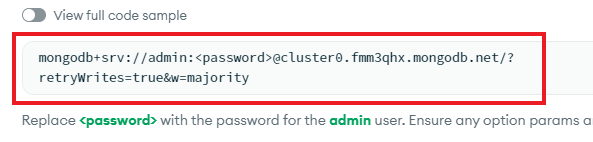
Replace the <password> placeholder with the password you created earlier for the admin user. This string is secret, anyone having access to it can read and write to your database. Copy the resulting connection string, which should look a little bit like this:
Now, that we've set up the database, lets use it to store the access tokens → this is commonly referred to as “storing sessions”.
After that import mongodb client constructor in your index.js like this:
After that create the database client like this:
In the beginning of the function connect the database client like this:
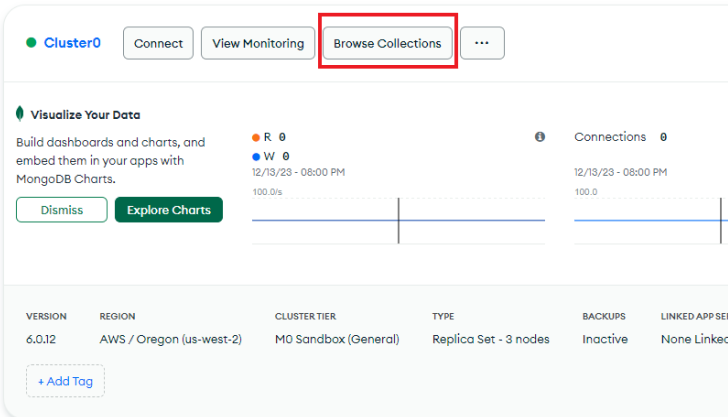
Now, you're saving the sessions token into the database. And you can view the records in your MongoDB dashboard if you click “Browse collections” and navigate to the “Session” collection.
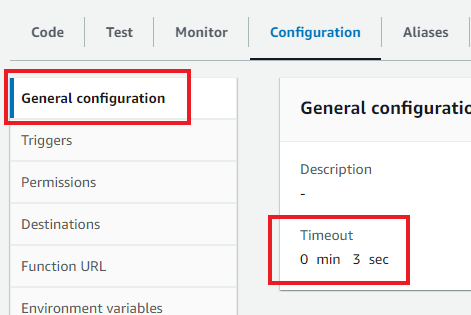
Now let's pack this function into a zip file and upload it to Lambda. As you might have notice when uploading the zip folder to Lambda, it got pretty big — 14MB. By default Lambda functions time out after 3 seconds, and since your function is huge, you have chances of hitting that threshold. To avoid that from happening, in your Lambda dashboard, navigate to the “Configuration” tab and in the General configuration change the default timeout from 3 seconds to 10.
Ok, now let's create our data endpoint — the function that would be returning data to our GPT. The function that is the actual reason of why we've done everything we've done so far.
Now that our backend is ready it's time to connect it to the GPT. For that we need to create the GPT, and then create an action for it, in which we'll specify the endpoint to call using the OpenApi schema. Head over to the “Explore tab” of your ChatGPT account.
Click “Create a GPT”, and then enter the 'Configure' tab.

Fill in the basic info such as the name and short description, and then at the bottom, click the “Create new action”.
In the top right, click “Examples” and select “Blank Template”.
This will populate a template. Copy it and paste into a text file. You can use Microsoft word or notepad. Then add a prompt to it like this:
Your final prompt should look like this:
Give it to ChatGPT. The reason why you're giving the template is because otherwise it may use an old version of the manifest, which is not advisable.
Edit the title and descriptions of the received manifest to help the GPT understand when it should call the endpoint and what data should it provide. As well as how to interpret the results. Also add a descriptive name as an 'operationId' to your route. This name will be displayed in the UI of the configuration, and you will be able to reference it when writing instructions for the GPT.
Copy and paste the manifest into the GPT's action.
You will see the operationId name populated in the UI.
Now click the little gear icon to the right of the Authorization row and then select OAuth
Fill in the params from the Google Console, and the manifest. You have all of these params at hand. If you have more than one scope enter them space separated.
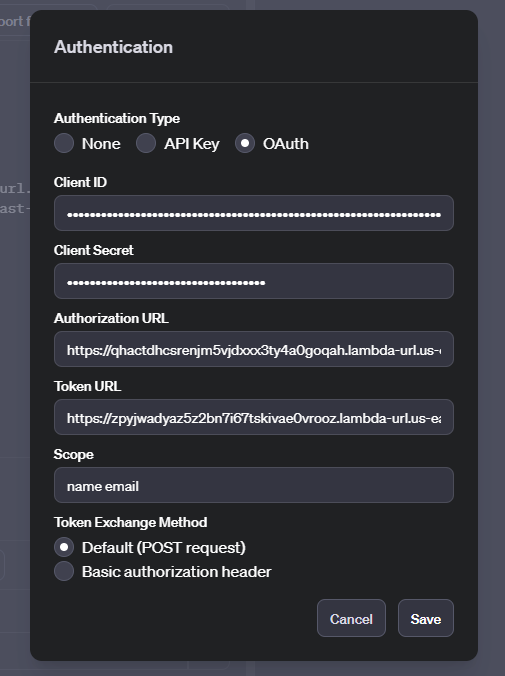
Click “Save”.
Now add a privacy policy url and click the green “Update button” in the top right corner.
After seeing that the GPT is successfully published click the return arrow in the the top left.

Now refresh the page. It's important.
Click “Configure”.

At the bottom you will see the updated callback url, you need to copy it and replace the placeholder we've put in the Google Console, as well as in our authorization and authentication lambda functions.
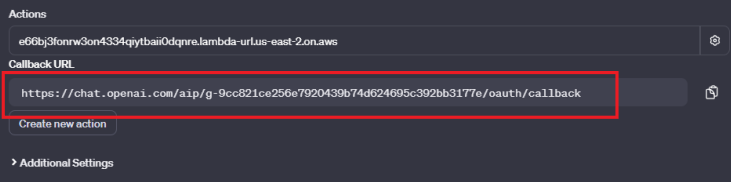
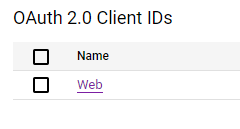
Go to https://console.cloud.google.com/apis/credentials and click your client under the OAuth 2.0.
Change the “Authorized URI” with the callback url from the GPT and click “Save”.
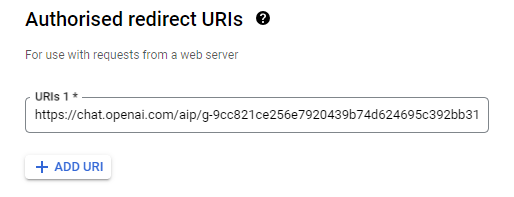
Make sure to do it in all functions.
Then zip your lambda functions and upload them to the Lambda again.
Every time you change something in your GPT's actions this callback URL will change and you will have to update it again. So try not to change the action's of your GPT, including it's authorization parameters often.
If you fail to update it you will be getting the “incorrect redirect uri error” on the google consent screen during the authentication.
Ideally you should be using environment variables to avoid rebuilding your code every time your credentials change. Feel free to implement this functionality using the dotenv package in your code.
Then in the lambda's configuration tab → environment variables section, add the variables like that.
.png)
The last step is adding instructions to your GPT. Head over to the “Explore tab” and click on your newly created GPT. In the “Configure” tab add the Instructions. Keep them short and to the point. Here is a basic example:
Add the instructions and click “Save”. Modifying the instructions doesn't change the callback URL, so you don't need to update anything when you do it. Cross fingers and test:
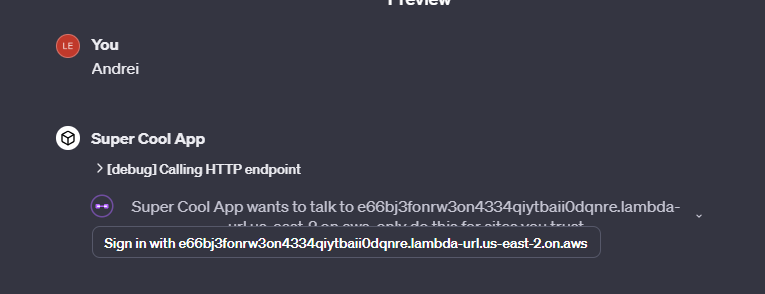
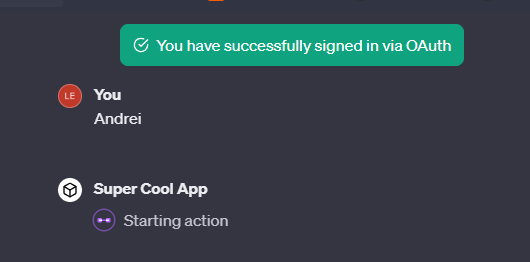
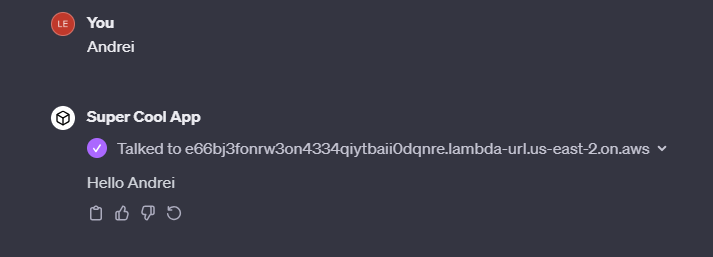
Thanks for reading!
Our examples of GPTs that are made using this method are:
Or you can check out all of our GPTs